Subsegment Comparisons Across Mashup Triads
This is a tool to compare the three songs (two sources and resultant mashup) in a mashup triad.
Each song's structure has been mapped using a self-similarity detection script to find and label stylistically distinct and similar subsegments of the song. The segments are labeled with letters along the top of each timeline. These letter labels only measure similarity within the context of a given song, and cannot be used to make comparisons across different songs.
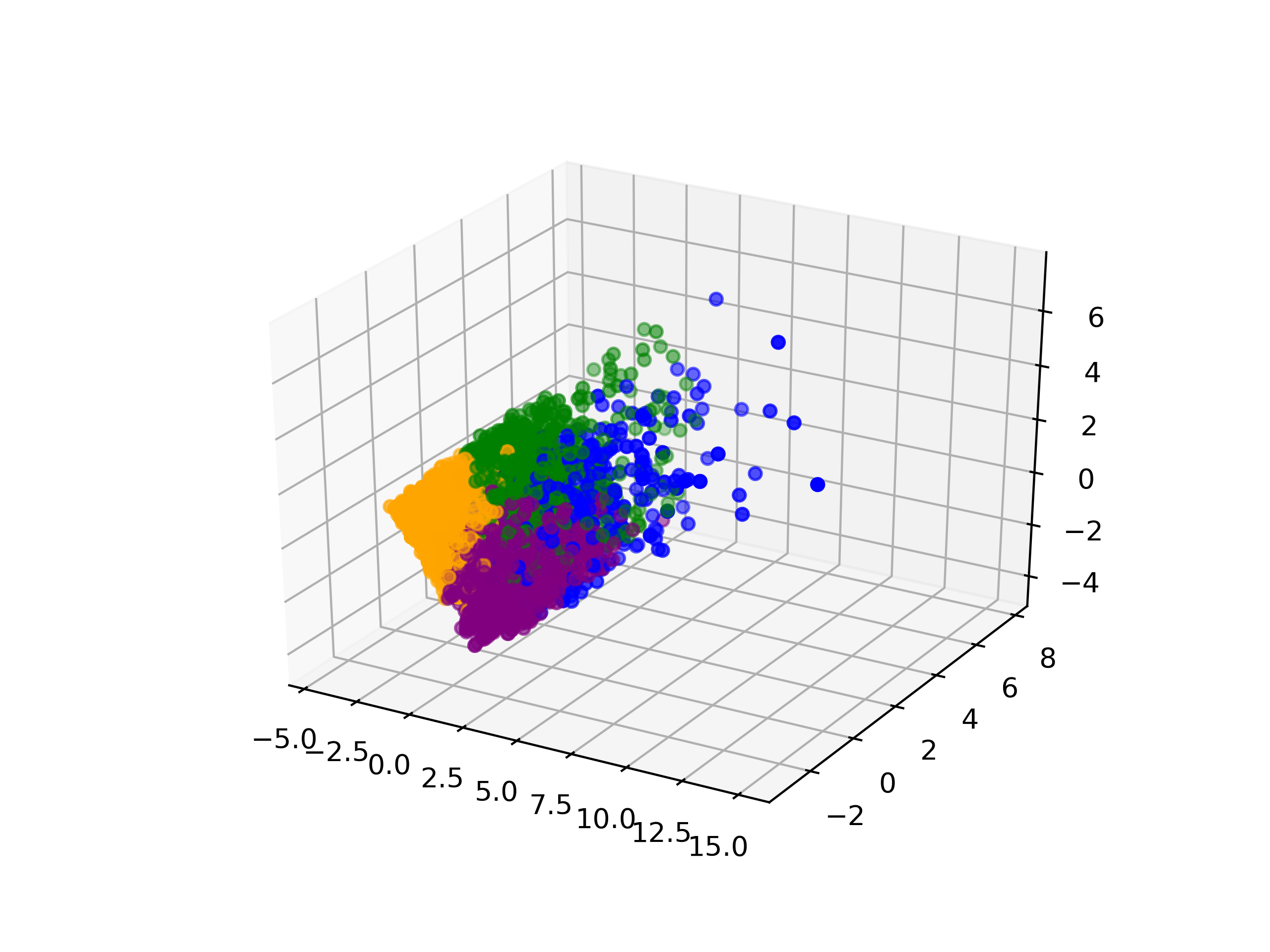
The subsegments of all of the songs in the 120-song mashup corpus (+240 sources) were clustered using k-means clustering, using extracted quanitative features (BPM, Lowest Note (Hz), Highest Note (Hz), Range (Hz), Total Duration of Most Common Chord,Chord Consistency, Number of different chords in segment, Duration (seconds), Start time (seconds), Stop time (seconds)). These clusters are denoted by the color and number assigned to each segment. The number/color labels are derived from comparisons across the whole corpus, and may be used to compare between different songs.
This tool may allow for analysis of movement of types of subsegment between source and mashup tracks.
General Cluster Statistics
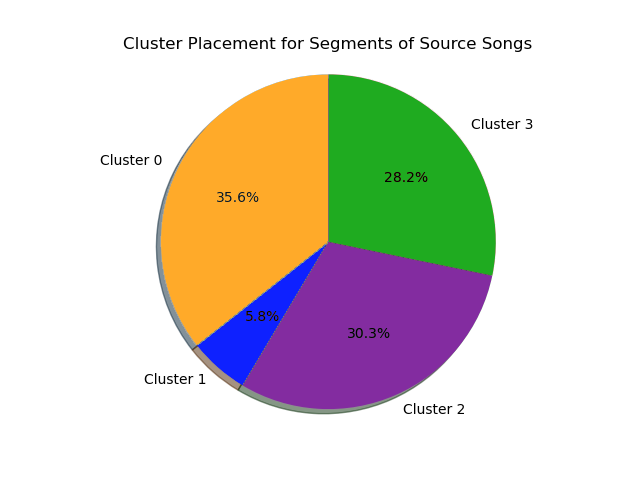
Comparison of Cluster Prevalence Between Source and Mashup Tracks:

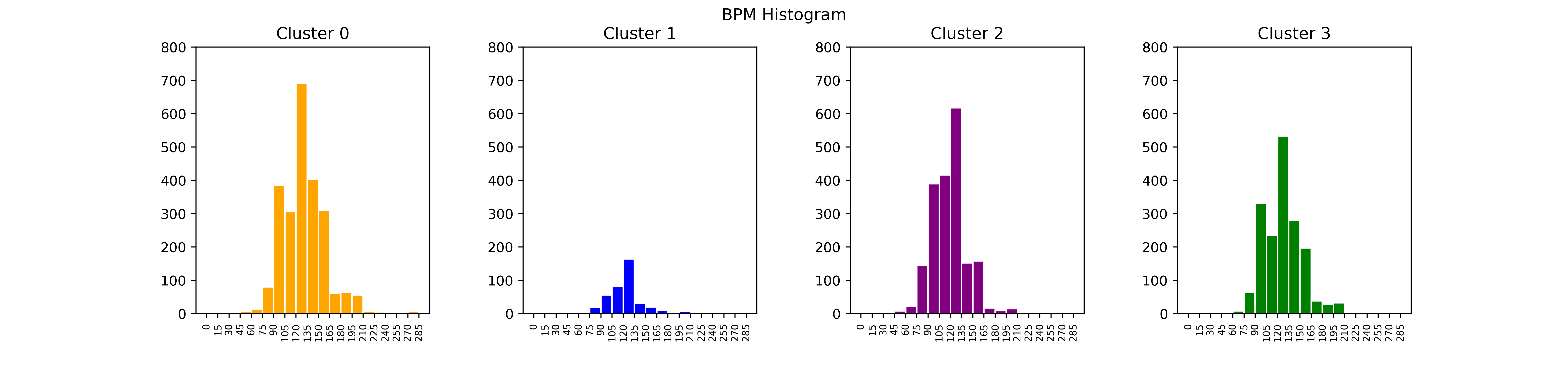
BPM Spread Between Clusters:
Chord Consistency Spread Between Clusters:

Range (Hz) Spread Between Clusters:

Duration Spread Between Clusters:

Machine-Derived Key + Third Distribution Between Clusters:
Machine-Derived Third Distribution Between Clusters:

Machine-Derived Most Common Chord Distribution Between Clusters:
Number of Chords Spread Between Clusters:

Primary Component Analysis of Cluster Scheme: