Remix Research Visualization
This page features tools and visualizations developed through machine-assisted research into pop music remixes by Eduardo Navas, Robbie Fraleigh, Alexander Korte, and Luke Meeken.
Two main sources of data were used in the analyses described here. Both corpuses included audio tracks of songs which were used for machine feature extraction.
The Free Music Archive (FMA) is a corpus of Creative Commons-licensed audio from 106,574 tracks from 16,341 artists. As the corpus includes a wide variety of tracks, including lengthy live recordings of performances, our feature extraction script excluded tracks over 20 minutes long, the analysis of which exceeded the memory limitations of the computing resources we were using, resulting in a corpus of 103,504 tracks. Only 2.9% of the FMA tracks were excluded by this criterion. Features were extracted from this corpus of tracks using the Librosa library, including key, range between lowest and highest notes, length, structural decomposition of the song into self-similar segments, beats per minute, chord progression. These features were used to generate different potentially-meaningful clustering schemes using k-means clustering in the scikit-learn library.
The other source of data was a curated selection of YouTube mashups and the source tracks used in them. Early in our analyses, a corpus of 30 mashups, used in Eduardo Navas’s prior (non-machine-assisted) analyses was used. This corpus was made up of “A+B” mashups combining two source tracks into a new track, and was curated by following the recommendations of the YouTube algorithm as popular mashups on the service were viewed. During our study, the corpus was expanded to include a total of 120 mashups (and their 240 source tracks) to provide more data for clustering and analysis, and to address potential issues of representation in the original corpus.
This research was made possible with grant support from The College of Arts and Architecture Office of Research, Creative Activity + Graduate Education, and The Institute of Computational and Data Sciences (ICDS), The Pennsylvania State University
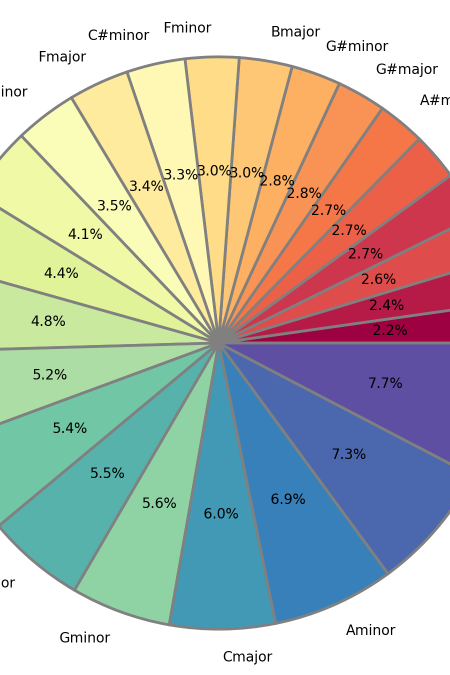
Mashup Clustering Navigation
This tool is dseigned to help surface songs from the mashup corpus for the various machine clustering attempts we've made at organizing the data, to facilitate qualitative evaluation of the clustering schemes alongside the extant quantitative evaluation.
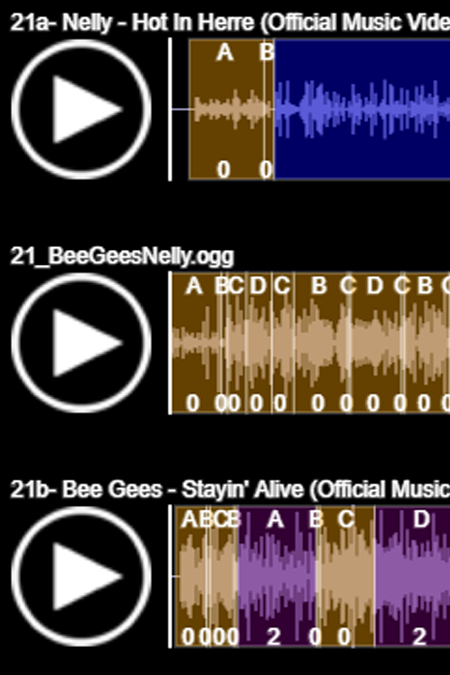
Subsegment Comparisons Across Mashup Triads
This is a tool to compare the three songs (two sources and resultant mashup) in a mashup triad.
Each song's structure has been mapped using a self-similarity detection script to find and label stylistically distinct and similar subsegments of the song. The segments are labeled with letters along the top of each timeline. These letter labels only measure similarity within the context of a given song, and cannot be used to make comparisons across different songs.
This tool may allow for analysis of movement of types of subsegment between source and mashup tracks.

Let it Be / No Woman, no Cry
An interactive visualization allowing for the navigation of a particular YouTube video mashup from the mashup corpus, juxtaposing different visualizations of extracted features.
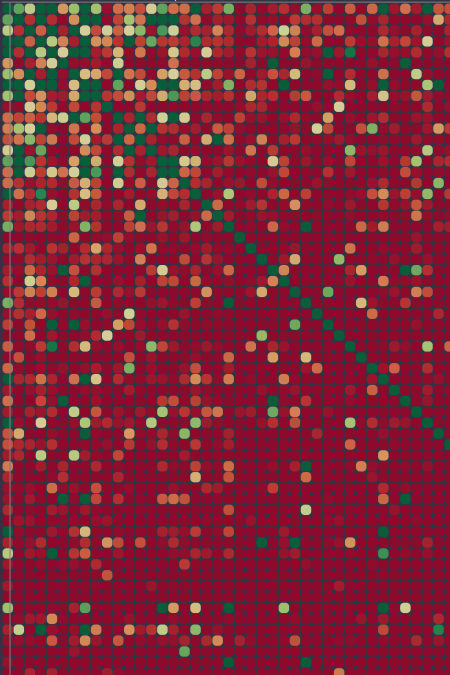
Genre Co-Occurrence in the Free Music Archive
This heatmap visualizes relationships between genres of songs included in the Free Music Archive (FMA).
Relationships were tracked by analyzing the ID3 metadata of all of the songs in the archive, and tracking how frequently songs of one genre occurred alongside songs of another genre in the body of work by the same artist. In this way, we could tally, for instance, how many songs categorized as "jazz" were produced by artists who also wrote songs categorized as "electronic."